scrapy利用selenium爬取今日头条新闻
安装scrapy,新建项目
首先安装scrapy,然后创建项目,这里就略过了,可以看我这篇文章scrapy创建爬虫项目步骤。
安装Selenium
pip install selenium
下载浏览器驱动
自行选择使用哪种方式,PhantomJS为无界面的浏览器。
Chrome驱动
官方下载地址为:https://chromedriver.storage.googleapis.com/index.html。
其他下载地址为http://npm.taobao.org/mirrors/chromedriver/。
如果官方下载地址无法访问,可以选择第二个下载地址。注意看自己电脑的chrome浏览器版本,查看notes.txt文件与驱动的适配版本是否一致。如下图:


PhantomJS驱动
进入PhantomJS官方网站(http://phantomjs.org/download.html),下载与操作系统相匹配的驱动。解压下载的压缩包,将文件夹bin里的phantomjs.exe文件放到Anaconda3的Scripts目录下。
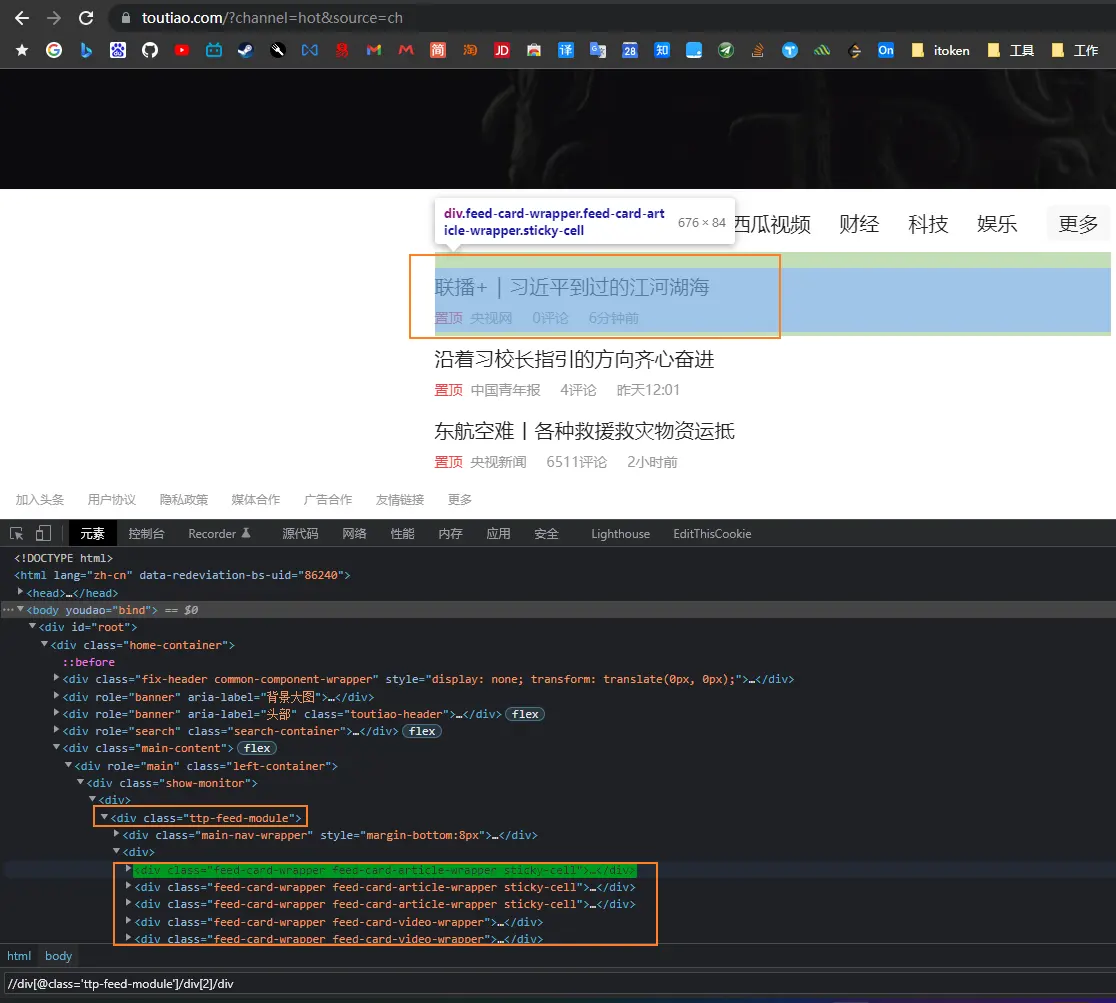
分析网页结构
我们只需要抓标题和评论数还有新闻来源,只要找到//div[@class='ttp-feed-module']/div[2]/div下面的数据就行,然后不断往下滑动滚动条,就能自动加载新闻。
代码
toutiao_spdier.py
import scrapy
from scrapy import Request
from toutiao.items import ToutiaoItem
from selenium import webdriver
class ToutiaoSpiderSpider(scrapy.Spider):
name = 'toutiao_spider'
def __init__(self):
# self.driver = webdriver.Chrome()
self.driver = webdriver.PhantomJS()
def start_requests(self):
url = 'https://www.toutiao.com/ch/news_hot/'
yield Request(url)
def parse(self, response):
item = ToutiaoItem()
list_selector = response.xpath("//div[@class='ttp-feed-module']/div[2]/div")
print(response.text)
for li in list_selector:
title = li.xpath(".//a[@class='title']/text()").extract_first()
source = li.xpath(".//div[@class='feed-card-footer-cmp-author']/a/text()").extract_first()
comment = li.xpath(".//div[@class='feed-card-footer-comment-cmp']/a/text()").re("(.*?)评论")[0]
item['title'] = title
item['source'] = source
item['comment'] = comment
yield item
# 退出
self.driver.quit()
这个文件,只是做了简单的解析工作,获取其中的字段。我们需要把webdriver初始化在构造方法中,然后接下来会在middlewares.py中使用。
middlewares.py
from scrapy import signals
import time
from scrapy.http import HtmlResponse
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.common.exceptions import TimeoutException, NoSuchElementException
# .... 省略其他方法,因为未做修改
def process_request(self, request, spider):
if spider.name == 'toutiao_spider':
spider.driver.get(request.url)
try:
wait = WebDriverWait(spider.driver, 30)
wait.until(EC.presence_of_element_located((By.XPATH, "//div[@class='ttp-feed-module']/div[2]/div")))
spider.driver.execute_script('window.scrollTo(0,document.body.scrollHeight/2)')
for i in range(10):
time.sleep(2)
spider.driver.execute_script('window.scrollTo(0,document.body.scrollHeight)')
origin_code = spider.driver.page_source
res = HtmlResponse(url=request.url, encoding='utf-8', body=origin_code, request=request)
return res
except TimeoutException:
print('time out')
except NoSuchElementException:
print('no such element')
return None
else:
return None
# .... 省略其他方法,因为未做修改
这里只是检测元素存在后,就开始滑动窗口,滑动10下之后,将页面的源码封装为HtmlResponse,交给spider的parse方法进行解析,就是上面的toutiao_spdier.py的parse方法。
settings.py
# 默认为True,改为False
ROBOTSTXT_OBEY = False
# 放开注释就行
DOWNLOADER_MIDDLEWARES = {
'toutiao.middlewares.ToutiaoDownloaderMiddleware': 543,
}
执行爬虫
scrapy crawl toutiao_spider -o toutiao.csv
可能遇到的错误
如果使用PhantomJS可能会遇到下面这个错误。
module ‘selenium.webdriver‘ has no attribute ‘PhantomJS‘
解决办法
新版的selenium已经放弃PhantomJS,所以才会出现module ‘selenium.webdriver’ has no attribute ‘PhantomJS’。我们需要降低selenium的版本。
-
先把selenium卸载,代码如下:
pip uninstall selenium -
安装selenium==2.48.0版本的,代码如下:
pip install selenium==2.48.0