scrapy创建爬虫项目步骤
安装scrapy
使用pip安装
命令如下
pip install scrapy
常见安装错误
因为系统环境的差异,在安装Scrapy时,有时会出现意想不到的错误。例如,使用pip安装Scrapy时遇到Microsoft Visual C++14.0 is required错误,如下图所示
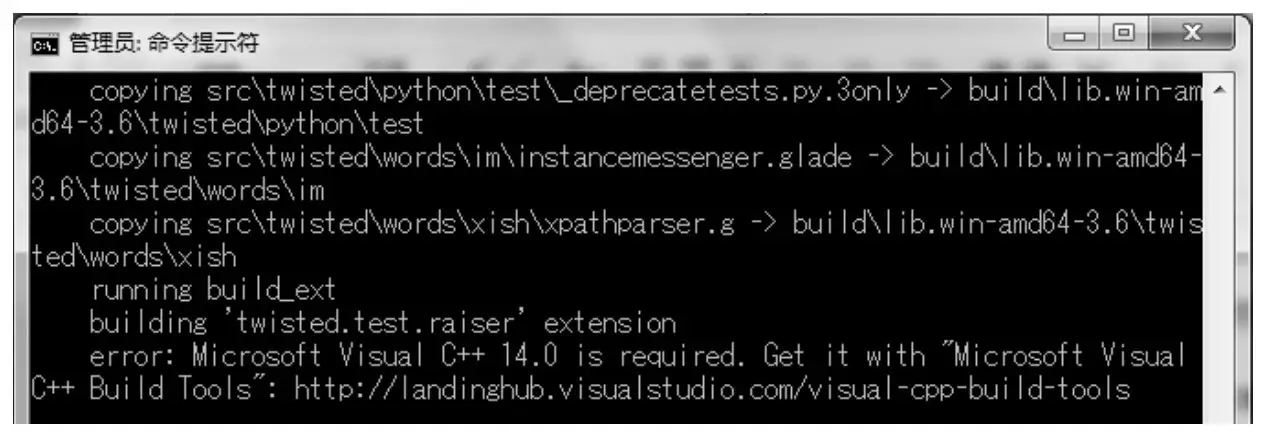
解决办法
方法1
可以使用conda安装,但是需要提前安装conda
conda install -c scrapinghub scrapy
方法2
根据提示可知,错误是由安装Twisted导致的,所以需要先安装Twisted。Twisted的下载地址为http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted,根据Python和操作系统的版本,选择对应的whl下载文件即可。其中,cp后面的数字是依赖的Python版本,amd64表示64位操作系统。下载完后,定位到Twisted安装包所在路径,执行以下命令安装Twisted。
pip install Twisted-19.2.0-cp35-cp37m-win_amd64.whl
成功安装Twisted后,就可以使用pip命令安装Scrapy了。
创建项目
-
首先创建一个存放项目的目录比如scrapyProject,然后进入这个目录
cd /d/PythonWorkSpace/scrapyProject -
创建一个scrapy项目,比如demo
scrapy startproject demo -
生成spider代码,格式:
scrapy genspdier 爬虫名字 爬取网页的地址scrapy genspdier example http://xxx.com/abc.html
利用scrapy shell 分析网页结构
我们可以利用scrapy shell ,来测试xpath,css等选择器,方便我们进行测试
scrapy shell http://xxx.com/abc.html
例如
In [3]: response.xpath("//div[@class='page-box house-lst-page-box']/
...: /@page-data")
Out[3]: [<Selector xpath="//div[@class='page-box house-lst-page-box']//@page-data" data='{"totalPage":100,"curPage":1}'>]
In [4]: response.xpath("//div[@class='page-box house-lst-page-box']/
...: /@page-data").re("\d+")
Out[4]: ['100', '1']
启动项目
我们可以在项目根目录输入命令来启动
scrapy crawl demo
或者在根目录创建一个python文件,里面的内容如下:
from scrapy import cmdline
cmdline.execute("scrapy crawl demo".split())
然后运行这个python文件也可以进行启动。
想要把获取的item保存为csv文件,可以在启动命令后面加上-o参数,比如scrapy crawl demo filename.csv。
scrapy创建爬虫项目步骤
https://www.zhaojun.inkhttps://www.zhaojun.ink/archives/1028